Release Summary - Nov 09, 2023
The following key features and improvements, along with bug fixes, have been released in Algonomy products in the release version 23.24 during Oct 29 - Nov 09, 2023.
Enterprise Dashboard
Shop the Look - Initial UI Preview in the Portal
We have introduced the initial UI preview of the "Shop the Look" feature in our portal. As a merchandiser, you now have the capability to preview product images and recommendations for the items featured in the "Shop the Look" section. This allows you to verify that the bounding boxes around products are displayed accurately, ensuring a visually appealing shopping experience for customers.
-
Effortless Navigation: The user-friendly interface empowers merchandisers to seamlessly navigate to the "Shop the Look" page for a preview of product images and recommendations within the displayed images.
-
Detailed Product Preview: By entering a product ID, merchandisers can access model images where models showcase various products. These images display bounding boxes around the products, with the default bounding box highlighted and similar product recommendations for the selected item. This allows you to examine product details closely.
-
Search and Discover: You can now search for specific products, such as jeans, and select a product of your choice. This reveals the product's bounding box on the image and provides similar product recommendations for each selected item.
Note: The "Shop the Look" feature is not yet available in the left-hand navigation menu.
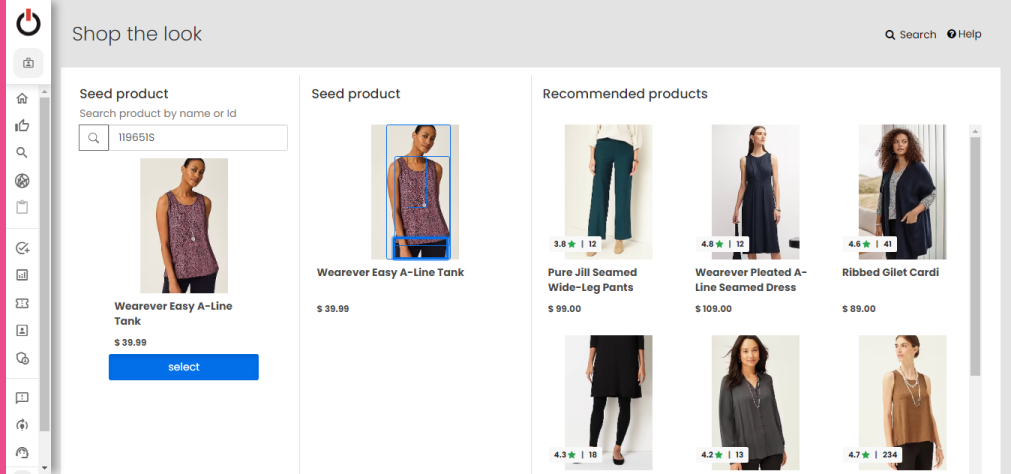
Jira: ENG-26344
Shop the Look - Regional Selection
With the "Regional Selection" feature, you can gain valuable insights into how similar items are displayed for different regions. We have added a dropdown menu that allows you to choose a specific region from a list of available options. This region selection serves as a reference point for customizing the similar items displayed alongside products within bounding boxes.
By selecting a region, you can view how similar items are presented to users in that specific area. This visibility enables you to fine-tune your product recommendations to cater to the preferences and trends unique to each region.
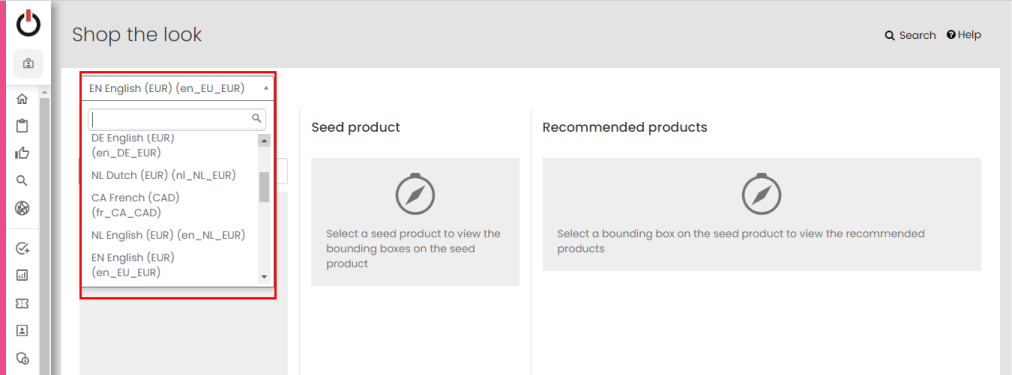
Jira: ENG-26580
Data Engineering
API to Expose Dynamic Experience/Social Proof Configurations
This new API provides social proof messaging final output as a response based on the UI setup (e.g., "10 people purchased today"). This makes it easy for clients on the server side or in apps to display social proof messages on their websites or apps. The API respects all configurations defined in the UI for determining which social proof messages to display.
What you can achieve with the API:
-
Focus on active Social Proof experiences - those currently active or Evergreen.
-
Access configurations from Social Proof experiences via the API. Retrieve context, API key, and other parameters.
-
Automatically pick the highest Importance experience, even when multiple experiences share the same location selector.
-
Identify the right experience based on context and segment parameters.
-
Configure metrics and messages at an experience/variation level.
-
Track experiences, log calls, and check if Social Proof messages are displayed.
-
Use it for Category and List Page templates.

Jira: ENG-25854
Data Engineering, Enterprise Dashboard
Email Recommendations Report - Active Campaigns
The Email Recommendations Report now allows you to focus on what matters most - active campaigns. With this update, the Email Recommendations Report smartly displays only those campaigns that have been active within your selected date range.
Now, when you access the Email Recommendations Report, you will find it tailored to your needs. You will only see campaigns that have had views within the date range you have set in your report filter. This ensures that your reports remain relevant and that you can focus on the most recent and impactful campaigns.
Jira: ENG-25795
Other Feature Enhancements
The following feature enhancements and upgrades have been made in the release version 23.24 during Oct 29 - Nov 09, 2023.
|
Jira # |
Module/Title |
Summary |
General Availability |
|
Enterprise Dashboard: Supported catalog enrichment with Column based feed files |
Previously, the roll-up process could only process row-based enrichment files if the customer's catalog feed was also row-based. However, the platform still only supports row-based enrichment files. Now, the roll-up process can still process row-based enrichment files even if the customer's catalog feed is column-based. Additionally, the roll-up process can now process internally developed enrichment attributes regardless of whether the customer's catalog feed is row-based or column-based. |
09-Nov-2023 |
|
|
Enterprise Dashboard: Catalog enrichment activation and configuration from siteconfiguration |
Currently activation of the catalog enrichment attributes roll up of internally developed NLP attributes require a separate activation process which needs OPS involvement. To resolve this, under site configuration, there is a flag 'enable catalog enrichment' -[check the screenshot attached]. 'Sync catalog with catalog enrichment' -The activation of the catalog enrichment attribute roll-ups will now be done by the activation of this feature. |
09-Nov-2023 |
|
|
Recommend: Send GlassView URLs for each placement in the recsForPlacements & personalize API responsesRecommend |
We have improved our system to better capture user interactions. Now, our APIs can seamlessly return GlassView URLs for richer insights into user behavior, enhancing your strategies with real user interaction data and delivering more personalized and effective content and placement strategies. |
09-Nov-2023 |
|
|
Recommend: New recsForPlacements and recsUsingStrategy params for Shop the Look |
Now, you can pass specific image and bounding box IDs as parameters in the recsForPlacements and recsUsingStrategy APIs. This empowers you to obtain tailored recommendations for precise product, image, and bounding box combinations when using the ShopTheLookStrategy or any compatible strategy. |
09-Nov-2023 |
|
|
Recommend: Create a new View-only API Client Keys privilege |
We have introduced VIEW_API_CLIENTS privilege that offers read-only access to your existing API Client Keys. This development streamlines your user experience, incorporated into specific roles, including Manage Merchandiser Rules, Advanced Merch Editor, Advanced Merch Publisher, Manage Promo and Connect, and Manage Content Rules. You can now conveniently access your API Client Keys on the client-facing Site Configuration page. Note: This privilege does not permit key creation or modification, maintaining the security and integrity of your data. |
09-Nov-2023 |
|
|
Data Reporting, Enterprise Dashboard: Generic page report -problem |
We have resolved an issue in the Generic Page report where data was not displayed as expected for specific sites. This problem has been investigated and resolved, ensuring that when you run the Generic Page report, it will now provide accurate and complete data. |
09-Nov-2023 |
|
|
Data Engineering: Update user segment and user attribute values in data store automatically |
We have implemented an upgrade to our data store management. Now, user segment and user attribute values are automatically updated via a robust data pipeline. For user segments, we now store both the segment ID and segment name, providing comprehensive information. User attributes are also managed more efficiently with key-value pairs for accurate tracking. Additionally, we have incorporated cleansing, de-duplication, and other administrative tasks to maintain data quality. To further optimize our data store, values that have not appeared in the last 6 months are automatically deleted. |
09-Nov-2023 |
|
|
Data Engineering, Enterprise Dashboard, Reporting: Benchmark Report - Data is not loading in QA and Prod |
We have resolved an issue that was affecting the accuracy of benchmark report values for a specific site. Now, the benchmark report data, including metrics like Rec % and Click-Through Rate in Sales by Channel, is being correctly displayed. |
09-Nov-2023 |
|
|
Data Engineering: Social Proof API - Show Importance (of experience) as part of new SP API response |
We have introduced an "Importance" parameter in the Social Proof API response. Now, when multiple experiences are available for the same context, you can easily identify the Importance of each one. This addition allows the system to prioritize and display the experience with the highest Importance. In cases where Importance is equal, the system selects a message randomly. |
09-Nov-2023 |
|
|
Data Engineering, Enterprise Dashboard: TS Reporting - Pass Pagetype as filter when all placements for a Pagetype is selected |
We have introduced enhanced report filtering for a smoother analytics experience. When you select a Page Type or multiple placements within a Page Type, our system now intelligently filters the results, providing you with accurate and relevant data. These improvements are seamlessly integrated into various reports, including Site Analytics, Placements, Strategies, and Recommend Segment. Plus, this enhancement is available for both On-Premises and Cloud reports. |
09-Nov-2023 |
|
|
Data Engineering: Category names were showing junk characters |
For a client, category names were showing junk characters instead of names. The issue has been resolved now. |
09-Nov-2023 |
|
|
Engineering: Added print statements in top X rollups. |
To help in better analysis added certain print statements for future use for modelbuildconfigs in:
|
09-Nov-2023 |
|
|
Data Engineering, Data Reporting, Enterprise Dashboard: Unable to get AM Rule Report's Details Report to Update |
We have fixed an issue related to the Advanced Merchandising Rule Report. Previously, when attempting to update the dimensions to be included in the report, the detailed report below failed to reload with the updated details as expected. Now, this problem has been resolved, and you can efficiently customize your AM Rule Reports to suit your requirements. |
09-Nov-2023 |
|
|
Data Engineering, Enterprise Dashboard, Reporting: find-stats-extractor not able to process click add2cart events |
We have resolved an issue related to event processing. Previously, there were problems with processing events, particularly those related to "click add2cart" events. Users encountered HTTP/1.1 response errors, specifically "HTTP/1.1 400". To address this issue, we have implemented a fix by adding the "follow=false" parameter for processing "add2cart" events. |
09-Nov-2023 |
|
|
Engineering>Feed Processing: Integrated enrichment feed processing pipeline with Feedherder with site configuration trigger |
Updated Feedherder to support the processing of enrichment files sent by the client. We had tagged the roll-up of enrichment files to catalog from the site configuration parameter - enable catalog enrichment. As enabling this feature also triggers the DS job and the image tag feature managed by the DS team, we did not want this configuration as the trigger point for enrichment using externally submitted files. Hence the site configuration parameter that triggers the catalog sync with the enrichment attributes has been changed to 'Sync catalog with catalog enrichment'. Both internally and externally submitted enrichment attributes will be rolled up once this flag is activated in the site configuration. |
09-Nov-2023 |
|
|
Engineering>Feed Processing: Created script to enable processing of client Enrichment Feed File via Feedherder |
Currently the process to enable enrichment feed file processing is manual and required executing some insert statements to update Feed profile. It is cumbersome for Ops to follow the steps. Hence created a script that Ops can execute to onboard a client. It will accept the siteid, file pattern, column delimiter and list delimiter. |
09-Nov-2023 |
|
|
FIND: Surface timeout error within Find response |
We have resolved an issue related to error handling within the Find response. Previously, if an Akka timeout occurred, clients were not provided with information in the response to indicate whether the timeout was transient. With this enhancement, we have added error type support in the response, offering "none" and "summary" options. The default value, if not specified, is "none." When "summary" is selected, only the summary is included in the response. |
09-Nov-2023 |
|
|
FIND: Make Solr collection replica count configurable in SFI |
Made Solr collection replica count configurable in SFI site wise. |
09-Nov-2023 |
|
|
FIND: Enabled search service access logs along with request latency |
Enabled the search service access logs along with request latency so that we can check which request is taking more time in search service. |
09-Nov-2023 |
|
|
FIND: Null Pointer Exceptions in Solr |
We have resolved an issue related to Null Pointer Exceptions (NPE) in Solr. Previously, there were numerous NPE errors in the Solr logs. This problem was specifically associated with a Solr plugin. With this fix, new snapshots will incorporate the latest version of the context-solr-plugin, eliminating these NPE errors and ensuring more robust performance. |
09-Nov-2023 |
|
|
Find, Find-EB: find-stats-extractor click and add2cart events to provide position value |
We have successfully resolved an issue related to event processing. Previously, when certain clients did not send "add to cart" events with a page number, it defaulted to 0. However, this caused discrepancies in event processing. Our solution entails changes in rrServer tracking ProductSearchTrackingApiV1.java, where we have now defaulted to -1 when the "page" parameter is not received. This ensures accurate event position calculations. We have also deployed find-stats-extractor version 1.12.18 to implement this fix. |
09-Nov-2023 |
|
|
FIND: Find Report - Search Vs Non Search KPIs |
We've made an enhancement to the Find Report, specifically focusing on Search vs. Non-Search Key Performance Indicators (KPIs). As a Digital Optimization Manager, you'll now be able to accurately view sales attributed to Find, regardless of the channel or region where the purchase is made after a search. Previously, purchases made through different channels or regions after a search were not considered as Find purchases. With this update, any purchase made after a search, even if the channel or region differs from the search view, will be correctly recognized as a Search purchase. Furthermore, attribution will now be performed for the purchase channel or region. This means that when you filter by a specific channel or region, the metrics displayed will be at the corresponding channel or region level. |
09-Nov-2023 |
|
|
Find: Pass QueryUnderstanding config in rrserver |
We have made a vital update by adding the QueryUnderstanding configuration to the Complementary Search JSON. This means that when using the Find API, you can now access the queryUnderstanding configuration from the complementary JSON. |
09-Nov-2023 |
|
|
Find: Make tagger and product schema analyser consistent |
We have implemented changes to ensure the consistency of the tagger and product schema analysis. By using the copy-paste query tag manage schema, we have aligned the analysis chain with the related product language analysis chain. This prevents any conflicts that may arise when clients use both query tags and custom analysis chains. Additionally, we now utilize the analysis chain from the product manage schema when creating the query tag collection. This flexibility allows clients to override the product manage schema with a custom analysis chain while ensuring the query tag collection utilizes the chosen analysis chain effectively. |
09-Nov-2023 |
|
|
Find: Partial phrase matching using querytag - prevent zero result |
We have made improvements to our query system. Now, when you search, you'll get more accurate results, even if your query is a partial phrase. To use this feature, make sure that the queryUnderstanding.reformulateQuery entry in your searchConfigJson is set to true. Additionally, if you include an fq (filter query) with a query tag-filtered property, your client-supplied filter value will be 'OR'd' with the query tag filter value, providing you with more flexible filtering options. |
09-Nov-2023 |
|
|
Find: Split Spellcheck query from Main Solr Query |
We have improved the speed of spellcheck queries in Solr. Now, when a request returns zero results and triggers a spellcheck, it won't slow down your queries. In case the spellcheck query times out, we'll provide an empty response instead of an error. This enhancement ensures a smoother and more efficient search experience |
09-Nov-2023 |
|
|
FIND: Consume NER feature in query time (Search service) |
We have enhanced our query understanding feature in the Search service. This improvement allows for more accurate and efficient search results. With the added configuration in complementary search JSON, you'll experience better query understanding, especially when filtering by attributes such as gender, brand, and size. |
09-Nov-2023 |
|
|
FIND: Brand (and other field) "Classfiers" - automatic filtering |
We have enhanced our filtering process to ensure a more precise shopping experience. Now, when a shopper performs a search, if an exact brand match is found among the search terms, the system will automatically filter the results to include only products from that identified brand. For example, if a shopper searches for "People Casual Trousers in Men," the search results will be tailored to display exclusively "People" brand products in the "Men" category. This ensures that the displayed products are highly relevant to the shopper's query, creating a more refined and precise shopping experience. |
09-Nov-2023 |
|
|
Find, Find-EB: e2e test for the statistics pipeline |
We have significantly enhanced our end-to-end testing for the statistics pipeline, ensuring the robustness and accuracy of our data handling. This update represents a critical step in our data pipeline project, ensuring smooth data flow and precise results. |
09-Nov-2023 |
|
|
Streaming Catalog: Introduced ability to process the ingested attributes within the defined character limitation |
When the product catalog is ingested, if the customer sends products with attribute values beyond the defined character limit, then the system should process with the limit enforced by the type of product attribute rather than rejecting the payload. Case in point, a customer has been ingesting products with attribute names beyond the 255-character limit (enforced by virtue of the name being a canonical attribute). All these products had been getting rejected and never made it to the product catalog. The issue has been resolved now. |
09-Nov-2023 |
|
|
Data Engineering, MVT: MVT eligibility is always true for placement and strategy rules clauses |
We have resolved an issue with MVT eligibility related to placement and strategy rules clauses. Previously, eligibility for certain rules was inaccurately evaluated. This issue has been rectified, ensuring accurate eligibility evaluations for tests using this type of rule. |
09-Nov-2023 |
|
|
Engage: Fallback for tag filter functionality |
We have enhanced our tag filter and refinement process to prioritize content matching, even if it means using lower-priority campaigns. This results in more relevant content for optimization managers. When the highest priority campaign doesn't contain matching content, our system will intelligently search through lower priority campaigns to find the right content. |
09-Nov-2023 |
|
|
Data Engineering: Extended Retention for MVT Reports |
In this enhancement, we've extended the retention period for crucial MVT reports including Category Metrics, Category Placement Metrics, Category Pagetype, and Placement Segment Metrics. This update has been implemented to minimize disk space usage within Cassandra node clusters and optimize system performance. |
07-Dec-2023 |
|
|
UPS: UPS API writer should fail and restart on any error during processing |
The UPS API writer now integrates a fail-and-restart mechanism upon encountering any errors during processing. This enhancement serves two key purposes:
|
07-Dec-2023 |
|
|
Find, Find-EB: Data-pipeline to be deployed as an App of Apps pattern. Change Stats and Tagging Charts to NodePort |
We've upgraded our data-pipeline deployment to utilize the App of Apps pattern, streamlining the management and deployment of Flink/Spark jobs and API services. This approach, detailed in this article about automating Argo CD, enhances system coherence and manageability. |
07-Dec-2023 |
Bug and Support Fixes
The following issues have been fixed in the release version 23.24 during Oct 29 - Nov 09, 2023.
|
Jira# |
Title |
Summary |
General Availability |
|
Enterprise Dashboard: Applied click-tracking fix to Submit button on the Guided Selling template |
Enabled click event to trigger on the Submit button of a Guided Selling quiz. On the default Guided Selling template, the click event triggers when the user submits the quiz (Submit button). |
09-Nov-2023 |
|
|
Enterprise Dashboard: Added input field for API client key back to Guided Selling. |
Input field for the API client key was inadvertently removed in Guided Selling, added back the input field for API client key as the preview in the UI does work without it. |
09-Nov-2023 |
|
|
Enterprise Dashboard: Interval value was populating as empty when tried to edit message type for purchases and add to cart |
Interval value was populating as empty when tried to edit message type for purchases and add-to-cart. The issue has been resolved now. |
09-Nov-2023 |
|
|
Recommend: Failures occurred to top views pipeline on master |
When log4j was initialized on a MR node, it failed to start because of a log4j exception. Fixed top views pipeline on master. The issue has been resolved now. |
09-Nov-2023 |
|
|
Recommend: Mesos job list page was not working. |
Mesos job list page was not working. The ops-console-UI was making the API call to oc-master to get the jobs info, the API call was taking more than 10 seconds, and the timeout value was hard coded in the ops-console-UI to 10 seconds, thus getting a timeout error. The issue has been fixed now. |
09-Nov-2023 |
|
|
Recommend: Products that were already viewed were again showing up as the recommendations |
Products that were already viewed were again showing up as the recommendations. The issue was with DNR restriction rule for ANF client. |
09-Nov-2023 |
|
|
Recommend: Top views pipeline performance optimizations |
Previously, events in this pipeline were duplicated, resulting in unnecessary resource consumption, with up to 8 duplicates being generated. We have successfully mitigated this duplication problem, drastically reducing it by up to 8 times. Our approach involves avoiding the duplication of regions, channels, or segments while maintaining the integrity of aggregation results. Additionally, we have introduced a new command-line argument that allows users to deploy the pipeline on Spark. |
09-Nov-2023 |
|
|
Engage: Error code was getting displayed to the user, instead of error message. |
When a user accessed the site URL, error code was displayed to the user instead of proper error message. The issue has been fixed now. |
09-Nov-2023 |
|
|
Engage: Discovered Audiences functionality was not working as expected |
In Discovered Segments, when ‘Discovered Audiences’ was turned on for few clients even after two weeks of potential execution, ‘Discovered Audiences’ was not capturing any audience data and it remained empty. |
09-Nov-2023 |
|
|
FIND: Wrong Site list was getting when a site was fetched from cluster view API with a specific cluster. |
If a user accessed sites API, it was showing all the sites in the ‘sites’ section. Wrong Site list was shown when fetched from cluster view API with a specific cluster, instead of showing only those sites which can go to the specific cluster. The issue has been resolved now. |
09-Nov-2023 |
|
|
FIND: Algonomy wizard was constantly burning CPU doing nothing. |
The Algonomy wizard has a class "TaskScheduler" that is broken and runs a hot spin-loop waiting for work and thus was constantly burning CPU doing nothing. The issue has been resolved now. |
09-Nov-2023 |
|
|
FIND: Excluded Querytag Operation, excluding single word |
Excluded Querytag Operation, which was earlier working only for single word excluding. |
09-Nov-2023 |
|
|
Engineering: Rollups in production were accessing QA nodes for modelconfig service. |
While validating rollup outputs after the recent release of rrMapreduce jar, it has been observed that the rollups (TopSellers, TopViews, TopPRoducts, TrafficCP and others possibly) were accessing QA nodes for model config service. The issue has been resolved now. |
09-Nov-2023 |
|
|
Data Engineering: Control was not showing up in production for any qualified users for MVT tests |
From 26th October, control was showing zero qualified visits. However, when unqualified flag is selected, it is showing the visits. This was happening for a few clients. The issue has been resolved now. |
09-Nov-2023 |
|
|
Advanced Merchandising: Import Adv Merch not working |
Resolved the issue with REI Adv Merch JSON import. The problem was identified in the JSON file where the placement name had a mismatch. The correct placement name is now used. After this adjustment, the JSON file can be successfully uploaded. |
09-Nov-2023 |
|
|
Find: Spike - Investigate invalid parameters requests |
During exception handling, we encountered a situation where the POST body was not logged, leading to difficulty in debugging requests, especially for a specific client using POST calls with external properties. We've resolved this issue by implementing a fix that ensures logging of the POST body during exception handling. |
14-Nov-2023 |
|
|
Recommend: Strategy message are not returned in the right language |
Previously, strategies were returning messages in the wrong language, displaying German instead of the expected French. The region, though identified as "fr" in the request, retrieved messages in the incorrect language. Additionally, regions were only available via IDs in the portal/database, lacking titles/names. The issue has been resolved to ensure strategy messages now correctly display in the specified language (French) as per the identified region. |
14-Nov-2023 |
|
|
Platform: RR Portal Reset password not working |
The RR Portal encountered an issue where password changes were not updating properly. Although users received a "successfully changed your password" message, the password didn't actually update. Subsequent logins using the new password resulted in login errors. The fix ensures successful password updates and proper login functionality, preventing the reuse of historical passwords. |
20-Nov-2023 |
|
|
RR Server: RecsForPlacement API extracts all product-region data for the response even when unnecessary |
During high server load, particularly with increased requests to recsForPlacement, the system faced timeouts and CPU spikes due to excessive extraction of product-region data. This occurred in calls to fillRegionData(), populating the ProductRegion object with numerous unnecessary product-regions, impacting performance significantly. To resolve this, we've optimized the API by implementing lazy loading for this data, fetching it only when necessary. This optimization prevents unnecessary extraction of extensive product-region details, ensuring more efficient handling of requests. The APIs now generate appropriate results while significantly reducing memory allocation and CPU usage during peak loads. |
28-Nov-2023 |
|
|
503 error |
Some clients encountered elevated response times on specific endpoints, leading to a 503 error across various API calls such as /personalize, /recsForPlacements, and /find/v1/. Investigation revealed increased traffic hitting NY and VA DCS (Data Collection Systems) primarily. We've addressed and rectified the root cause behind the 503 errors experienced by optimizing the backend infrastructure. |
28-Nov-2023 |
|
|
Outage Monday 11/27 - SF and RDN |
An outage affecting multiple clients in SF and RDN data centers was reported, leading to service disruption. To swiftly address this, an optimized version of the rrServer was deployed. This remedial action resolved the outage, restoring normal functionality for affected client calls. |
28-Nov-2023 |
|
|
Science: Catalog Enrichment - When using ChatGPT we don't see the new attributes |
We have resolved an issue in our Catalog Enrichment feature where new attributes from ChatGPT were not visible in the database. This problem was addressed with a backend API change, ensuring that all additional attributes are now properly displayed and accessible. |
07-Dec-2023 |