Release Summary - July 14, 2023
The following key features and improvements, along with bug fixes, have been released in Algonomy products in the release version 23.16 during July 04 – July 14, 2023.
Enterprise Dashboard
Improved Campaigns Search by Label
The Campaigns Search by Label feature has been improved to address the issue of labels getting disappeared from the search field, resulting in limited search results for the first searched label. With the latest improvement, we have resolved this issue and improved the search functionality. Users can now search for campaigns using labels without any disruptions. This enhancement ensures a smoother user experience and helps in more efficient campaign management.
Jira: ENG-26352
Enhanced Social Proof Message Display and Log
Digital Optimization Managers can now track and log the display of social proof messages to gain insights into their effectiveness.
For this enhancement, we have implemented the following changes:
- Tracking Social Proof Message Display: A new parameter, "isSpMessageShown," has been added to track whether the social proof message is displayed to the user during their visit. This parameter will be updated based on the presence or absence of the social proof message.
- Logging Social Proof Message Display: The "isSpMessageShown" flag has been added to track experience calls for item page, cart page, and category page. If at least one of the products meets the threshold, the flag will be set to true.
These enhancements provide valuable data for Multivariate Testing (MVT) and Dynamic Experience Reports, allowing for better analysis of the impact of social proof messaging on Revenue Per Visit (RPV) and conversion rates.
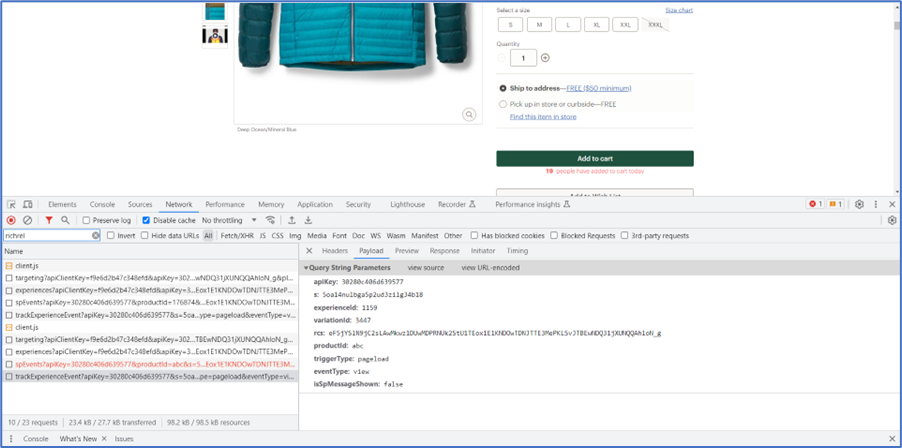
Jira: ENG-24542
Improved Display of Start Date in Boost Rules
Issue related to the display of start dates for boost rules. Previously, the start date was not fully visible even when expanded. To resolve this, we have increased the column width to ensure that the start date is displayed properly.
The start date for boost rules was not fully visible even when the columns was expanded, to resolve the issue, we have increased the column width to ensure that the start date is displayed properly and visible fully.
Jira: ENG-26288
Allowed Use of Single and Double Quotes for Attribute Values in Guided Selling
In this release we have allowed the use of single and double quotes for Attribute Values in the Guided Selling quiz. The permission helps the digital merchandisers to represent size of a product, such as a television, in inches.

Jira: ENG-26315
General Availability: Not yet available
Co-occurrence Report UI Enhancements
In this release, we have made significant UI changes to the Co-occurrence Report feature. Digital Optimization Managers can now easily view the categories that are commonly purchased together with the primary category, providing valuable insights for driving promotions and campaigns.
The updated UI includes options for selecting the Lookback Period, Primary Category, Metric (such as Attach Rate or Co-purchase Count), and Chart Type. Additionally, a detailed table with raw data is now accessible by clicking on View Report Details.
Jira: ENG-25524
Engage
Personalize API - Sort Content Based on List of Content IDs
The Personalize API now supports sorting content based on a provided list of content IDs. Personalization managers can pass a list of content IDs in the API call and receive the personalized order of content in the response. This feature gives control over what is content is returned, allowing for flexible ranking and selection from a subset of content without setting up separate campaigns. The returned content is the intersection of the selected campaign and the provided list of content IDs. In the API call, just include the list of content IDs (content_ids) as a pipe-delimited parameter...
Jira: ENG-25861
Identity & Access Management, UPS
Migrated External-Facing User Profile API to Kong Gateway
The External-Facing User Profile API has been successfully migrated to the Kong gateway. Customers can now access the API using OAuth 2.0 authentication, providing enhanced security and streamlined management of credentials and access scopes. The migration enables the setup of security measures at the service/site ID level and facilitates tracking of API usage and number of calls to the UPS reader endpoint. With this migration, customers can enjoy a seamless and unified experience while managing UPS API services using a single set of credentials.
Jira: PLAT-3472
Find & Streaming Catalog
Wisdom of Crowd Enrichment Deployment
In this release, we have successfully deployed Wisdom of Crowd (WoC) through the enrichment service. This involved several tasks, including the design and creation of a new WoC attribute spark job, integration of WoC attributes in SFI and search service, implementation of Datadog Metrics in the WoC SparkJob, and end-to-end testing of the WoC feature.
Jira: ENG-25232
Other Feature Enhancements
The following feature enhancements and upgrades have been made in the release version 23.16 during July 04 – July 14, 2023.
|
Jira # |
Module/Title |
Summary |
General Availability |
|
Find: WOC attributes solr query changes in Search service |
When Wisdom of Crowd (WOC) attribute is enabled for the site and snapshot, WOC attribute is added in the site search configuration to be used during the Search service. WOC feature has been enriched to overcome this issue. |
14-Jul-2023 |
|
|
Find: Integrate Datadog metrics in WOC Spark Job |
We have integrated Datadog metrics in Wisdom of Crowd spark job. |
14-Jul-2023 |
|
|
Find: Support needed in debugging the synonym Atea (1762) Production |
Support needed in debugging the synonym Atea (1762) Production. Solr document is indexed without using any synonym logic. At query time, using query=skærmskyd, the query synonym logic comes in action, and it converts skærmskyd to panzerglass,skærmskyd. Hence the response SE_2097444 is shown when searching with skærmskyd. Now this behavior is correctly working as implemented in Find. |
14-Jul-2023 |
|
|
|
Find: Wisdom of Crowed attribute integration in SFI |
WOC integrated with enrichment fields. If a snapshot is subscribed to a particular enrichment calculation, on completion of it all the enriched properties will be appended along with search schema.
Hence forth, it will be used as a schema field, as other existing schema fields are used currently. Search service will use it while adding WOC attributes to the Solr query. |
14-July-2023 |
|
|
Find: Design new Wisdom of Crowed attribute spark job |
WOC Aggregator originally sourced from CORE rrMapReduce WisdomOfCrowdsAttributesJob. This Job reads the data from search_to_view and search_to_purchase directories and calculates the WOC attributes. Wisdom of the Crowd Spark job is scheduled to run daily and generate the woc data from search events and calculates the normalized scores. |
14-July-2023 |
|
|
Recommend: |
An internal penetration test has revealed a potential vulnerability related to the log4shell CVE. The ops-console had been patched to log4j 4.17.0, but not 4.17.1 with the full complement of fixes. This update addresses the issue of existing deployed code unable to make an external call out to a monitoring server in the same fashion as the penetration test demonstrates due to incomplete patching. |
14-July-2023 |
|
|
Platform: Enrichment2 Tables Creation |
We have successfully created the required tables under the enrichment2 schema. The tables include calculations, calculation_datasets, calculation_groups, calculation_properties, calculation_details, and calculation_subscriptions. These tables are organized under the enrichment2 schema and are ready for use. |
14-July-2023 |
|
|
Find: Personalization Removal from facetsOnly Response Style |
In order to optimize performance and resource utilization, we have made the necessary changes to remove personalization from the facetsOnly response style. The request now accurately reflects the expected behavior, ensuring that personalized search is disabled for these types of requests. |
14-July-2023 |
|
|
Streaming Catalog: Direct Cancellation of Ingesting/Finished Datasets |
We have made an enhancement to the system that allows for the direct cancellation of ingesting or finished datasets without the need to publish them beforehand. This adjustment eliminates the potential risk of publishing a dataset that is already in a known failed state. With the new implementation, you can now cancel an ingesting or finished dataset by making a POST request to the specified API endpoint. The canceled dataset will be purged and eventually marked as DELETED. Note: Live datasets can still only be archived, as per the existing functionality. |
14-July-2023 |
|
|
User Profile Service: UPS Order Return Event Handling |
We have made changes to the User Profile Service (UPS) to enhance the handling of order return events. The UPS writer now supports both older and newer specifications of kryo serialized events, accommodating changes in the event structure. Additionally, we have updated the profile blob serialization/deserialization flow to support easy addition of new fields in the future. The UPS reader API now includes a new attribute "returns" in the JSON array response. |
14-July-2023 |
|
|
Data Engineering: Error Handling for Data Transfer from S3 to Redshift |
In this release, we have implemented error handling mechanisms to ensure smooth and accurate data transfer from S3 to Redshift. Specifically, we have addressed two specific scenarios: · Email_metrics: Handling string columns that may contain special characters such as tabs or newline characters in the values. · Replenishment_initial_data: Handling datatype mismatch cases to prevent errors during the data transfer process. |
14-July-2023 |
|
Find: Enhanced Datadog Metrics Integration |
We have integrated channelId and regionId into Datadog metrics for better monitoring and analysis of failures. The channelId parameter has been expanded to include 85 different combinations, which have been flattened into a single string format. It comprises userType (OpenWeb, RegUser, AstUser, Admin, External), pageType (Search, Category, Manufacturer, Menu), and filtered options (none, f). The regionId parameter has also been incorporated for the eshop region, with values such as LT, NO, and SE. |
14-July-2023 |
|
Bug and Support Fixes
The following issues have been fixed in the release version 23.16 during July 04 – July 14, 2023.
|
Jira# |
Title |
Summary |
General Availability |
|
Find: Fixing streaming chain query time for Scandinavian languages |
In batch processing, stemming runs before normalizing. In streaming chain, it runs differently. Hence, streaming chain is made same as batch processing and fixed streaming chain query time for Scandinavian languages. |
14-Jul-2023 |
|
|
Find: Query time Synonyms do not work with stopwords |
When using hon-lucene-synonyms for query time synonyms, two chains, solrconfig.xml before synonym expansion in the query parser and query analyser itself from the schema will run. Stopwords are already removed in the query parser from the schema, so they need not to be removed in solrconfig.xml. solrconfig.xml is equivalent to batch's schema text_syns index time processing which are used to expand synonyms. Neither Batch's text_syns index time analyser removes stopwords nor solrconfig.xml analyser for hon-lucene. This issue has been fixed now. |
14-Jul-2023 |
|
|
|
Enterprise Dashboard: Maximum Number of Total Views Enhancement |
The issue with editing and changing the maximum number of total views in the 'Content Catalog' has been resolved. Users can now successfully modify the total views for content within the catalog. |
14-July-2023 |
|
|
Enterprise Dashboard: Placement Selection Fix for AM Rules
|
We have addressed the issue where AM rules were unable to be saved due to non-existing or deleted placements. The bug in the placement selector component has been resolved, ensuring that only non-existent placements are filtered out, allowing for successful saving of AM rules. Users can now re-select the placements in the selector and save the rules without any issues. |
14-July-2023 |
|
|
Enterprise Dashboard: Model Browser Page UI Fix |
We have resolved the issue where the site drop-down and product field were overlapping on the model browser page. The necessary fixes have been implemented, ensuring a proper and seamless user interface on the model browser page. |
14-July-2023 |
|
|
Find: Find API Error Fix for a site |
We have addressed the issue where Find API calls were resulting in 500 errors for a particular site. The necessary fixes have been implemented, ensuring that the Find API calls now work without any errors for this site. |
14-July-2023 |
|
|
Find, Streaming Catalog: Resolution for SFI Restarting Issue with Identity Service |
During the ingestion of items with an allowList containing more than 50k externalIds, the Identity Service experienced a timeout while processing this large dataset, resulting in the shutdown of SFI. After thorough investigation, we identified the limitation in the size of the product within the ingest service. We have addressed this issue, and the problem has been resolved, ensuring the smooth functioning of SFI. |
14-July-2023 |
|
|
Recommend: Performance Improvement in Top Views Pipeline |
We have optimized the top views pipeline to improve performance by reducing the size of the event stream. Previously, events were duplicated multiple times, leading to unnecessary overhead. With our enhancement, we have eliminated region duplication and doubled up aggregation results, effectively reducing the event stream size by up to half. |
14-July-2023 |